Importing CSV with Power Automate


Table of contents
Have you ever tried to import a CSV file to SharePoint without Power Automate? It's like trying to eat soup with a fork - messy, frustrating, and ultimately unsatisfying. But fear not, dear reader! With the power of automation on our side, we can avoid the indignity of manual data entry and embrace the efficiency of machines. So sit back, relax, and let's learn how to import CSV files like the tech-savvy superheroes we are (or at least, like the tech-savvy sidekicks of superheroes).
Data review
First thing first - check your data. And I mean vigorously - what is the delimiter, what are the columns, does your delimiter appear in any of the columns (say we have a CSV delimiter "," and full name column where some names are in format "John,Doe").
The fastest way to do that in my opinion is open the file with a text editor.

The example file is delimited but also has quotation marks.
Flow
For this task, I want to upload the file to a document library, take the data from it and import it to a SharePoint list. Start the flow like this:
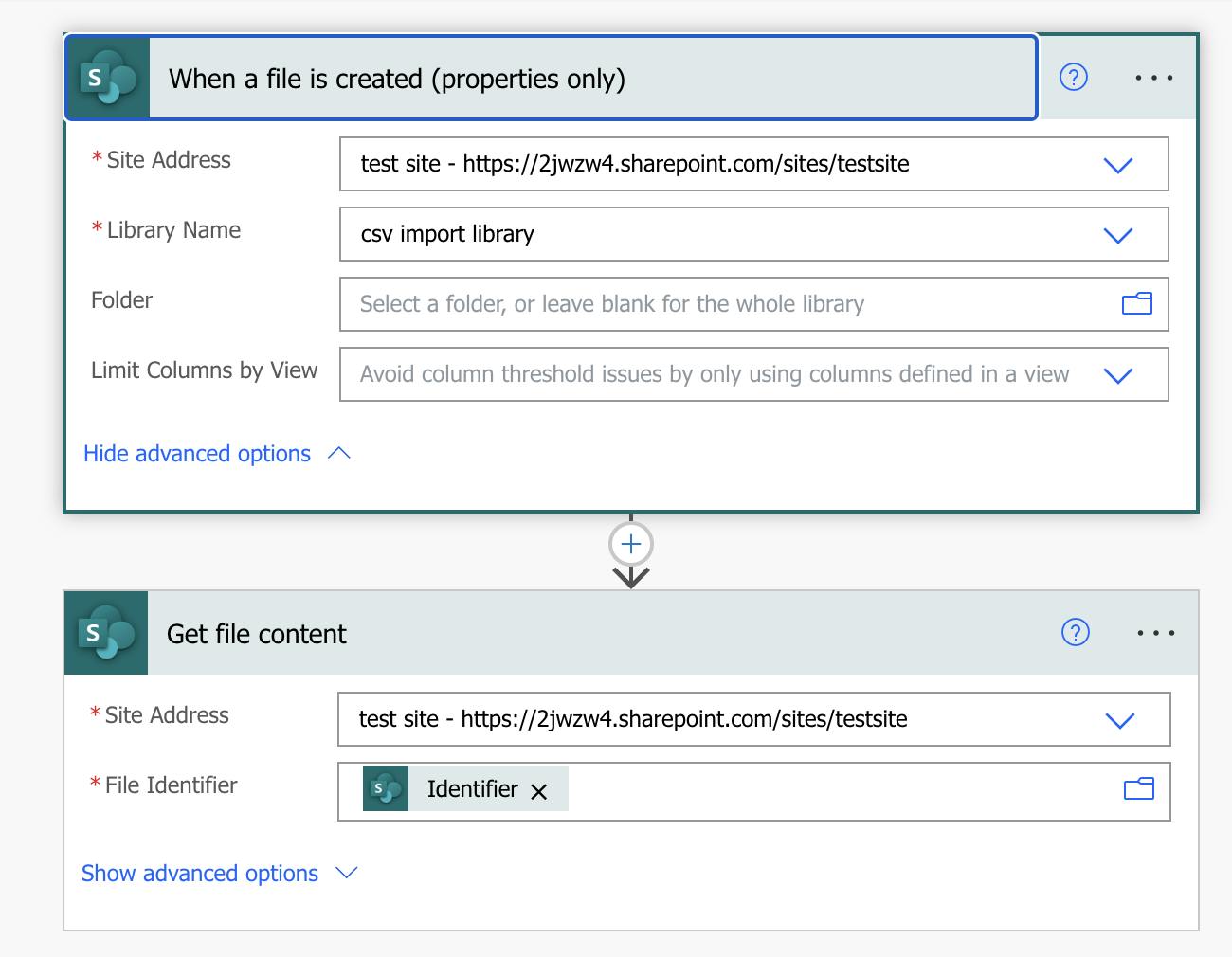
Then after we get the file content, we will need to fix the CSV content.
First Compose turns the output to a String.
string(outputs('Get_file_content')?['body'])
Second compose replaces the quotation marks with blanks.
replace(outputs('Compose'),'"','')
Third compose creates a line break. Just enter space and save.
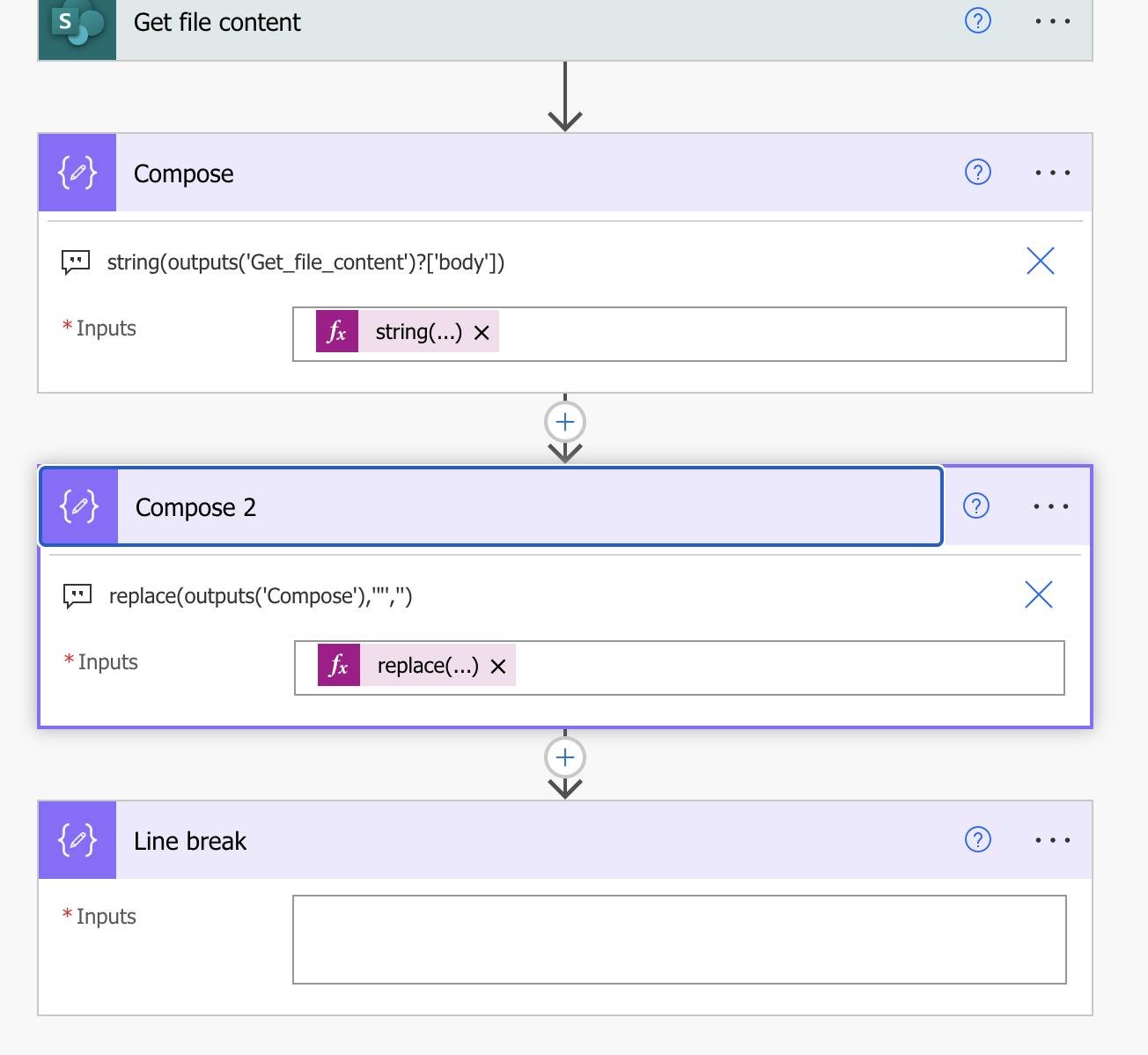
Now we need to split the rows of the file and compose our column names.
The "split" function in Power Automate is used to split a text string into an array of substrings based on a delimiter. The function takes two parameters: the first parameter is the text string that you want to split, and the second parameter is the delimiter that you want to use for splitting the text.
For the column names we want to take the first element of the array of outputs from the "Split rows" action, and split it into substrings.
split(outputs('Compose_2'),outputs('Line_break'))
split(first(outputs('Split_rows')), ',')
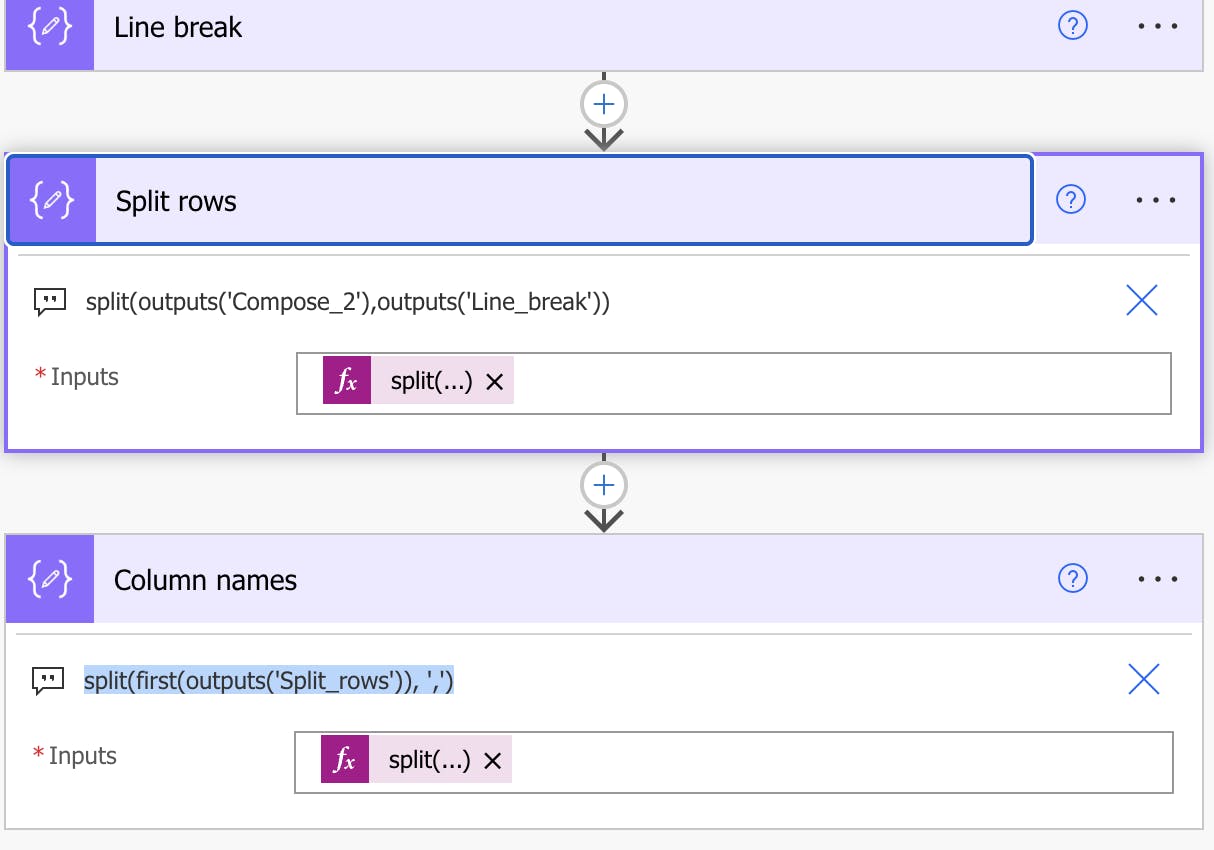
Now since we have an array, we need to map the columns to each line:
The From function is selecting all but the first element of the array output from the "Split rows" action, and then skips the very first element of that selected array.
skip(take(outputs('Split_rows'),sub(length(outputs('Split_rows')),1)),1)
outputs('Column_names')[0]
split(item(), ',')?[0]
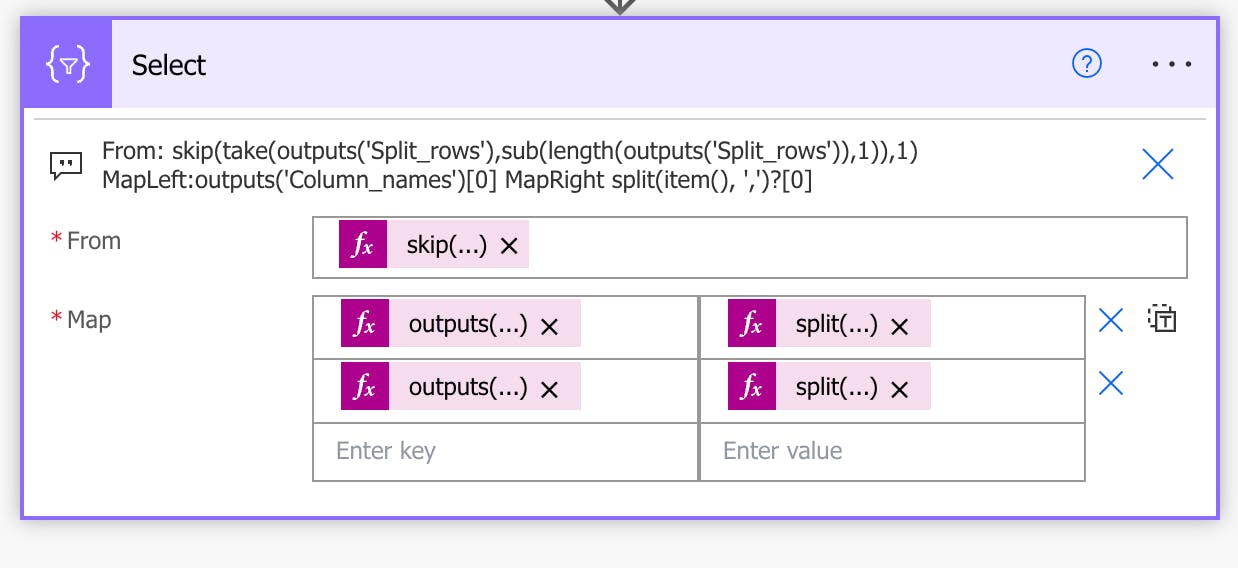
After completing this step, run the flow so that we can use the output for the next JSON schema.
Copy the output of the select action.
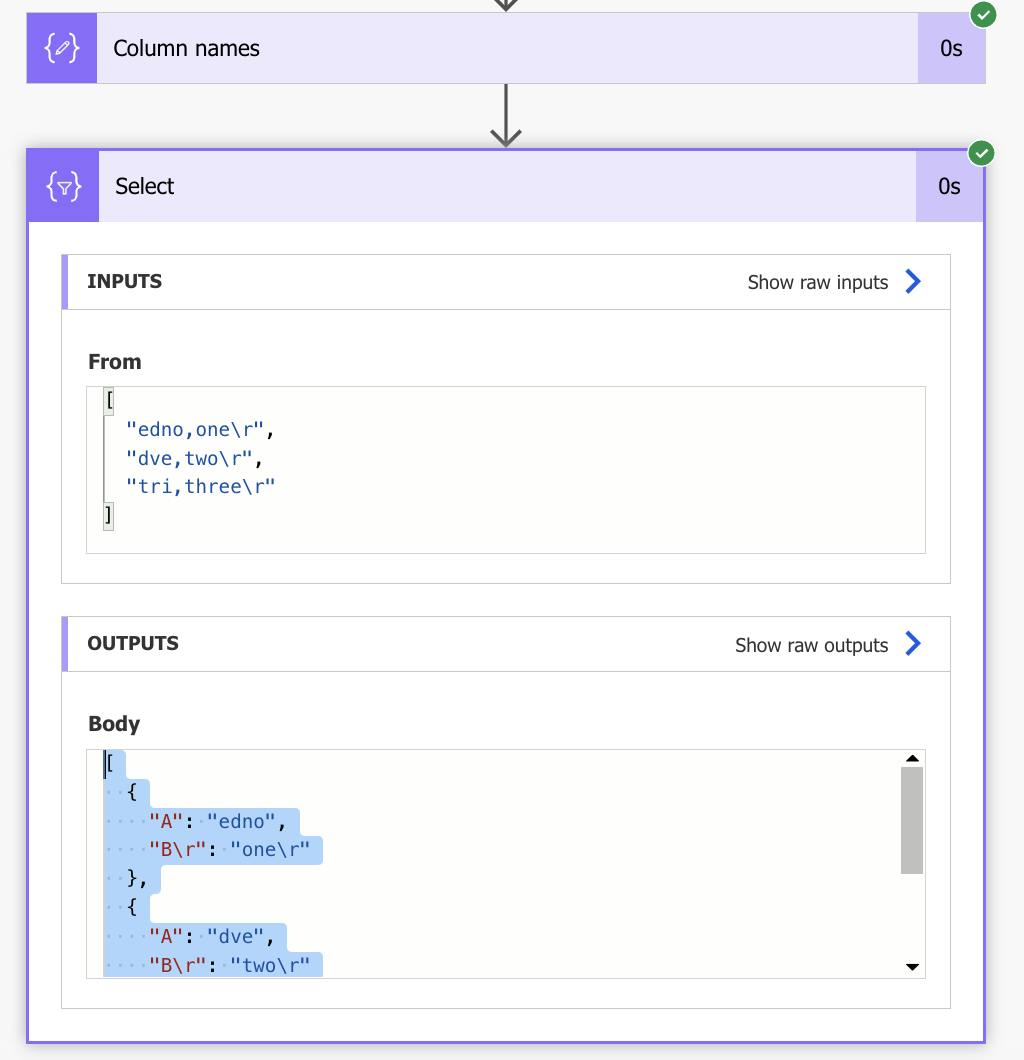
Now let's parse the JSON:
Content is going to be the output of the previous select action and after clicking generate from sample, paste the output you copied.
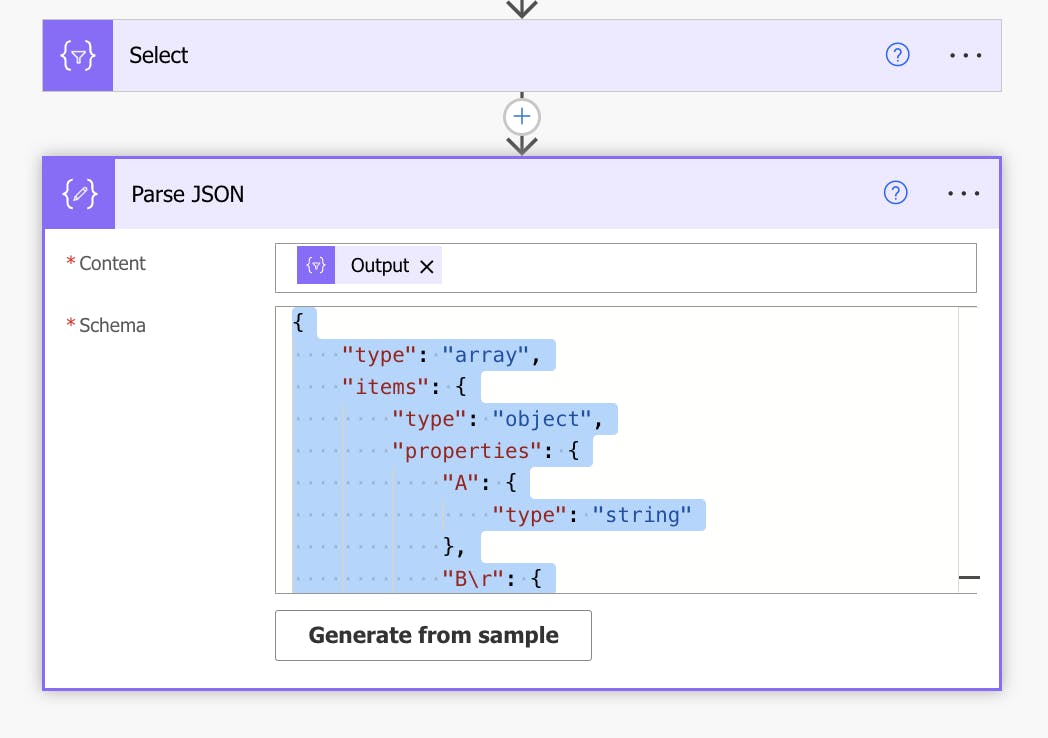
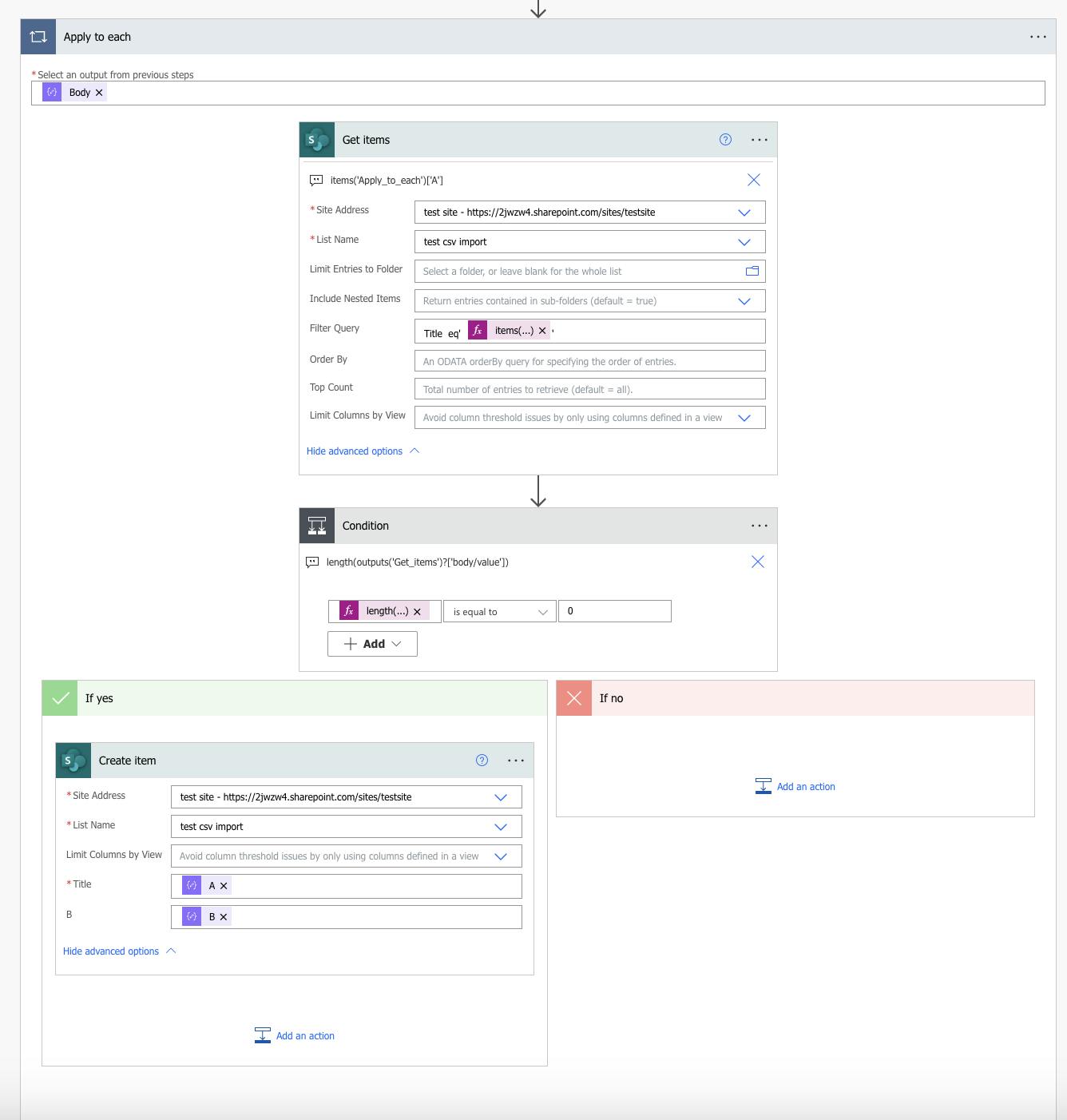
Then you can add the data to your Sharepoint columns with the create item action where next to each column you should add the dynamic content from the parse JSON action or if you'd like to go the extra mile, check for duplicate values before importing:
Use the apply to each action to go through each element of the parse JSON action body. Then use a get items action to check if the first column(or whichever column you want to check for duplicates) contains equal elements to any of the elements under a given column of the JSON action.
items('Apply_to_each')['A']
Then add a condition to count the number of items equal to the current one in the Sharepoint list. If the number is equal to 0 - create.
items('Apply_to_each')['A']
Hope this was helpful :)